Let’s solve BipedalWalker with PPO
This is an implementation of PPO with continuous actions, a new algorithm developed by OpenAI that has been used in OpenAI Five to play Dota 2.
PPO is a policy gradient method that differently from the vanilla implementation, it combines the sampling data through interaction with the environment and the optimization of a surrogate objective function. Read the paper to learn more about it.
For the DQN implementation and the choose of the hyperparameters, I mostly followed the paper. (In the last page there is a table with all the hyperparameters.). In case you want to fine-tune them, check out Training with Proximal Policy Optimization
Learn the theory behind PPO
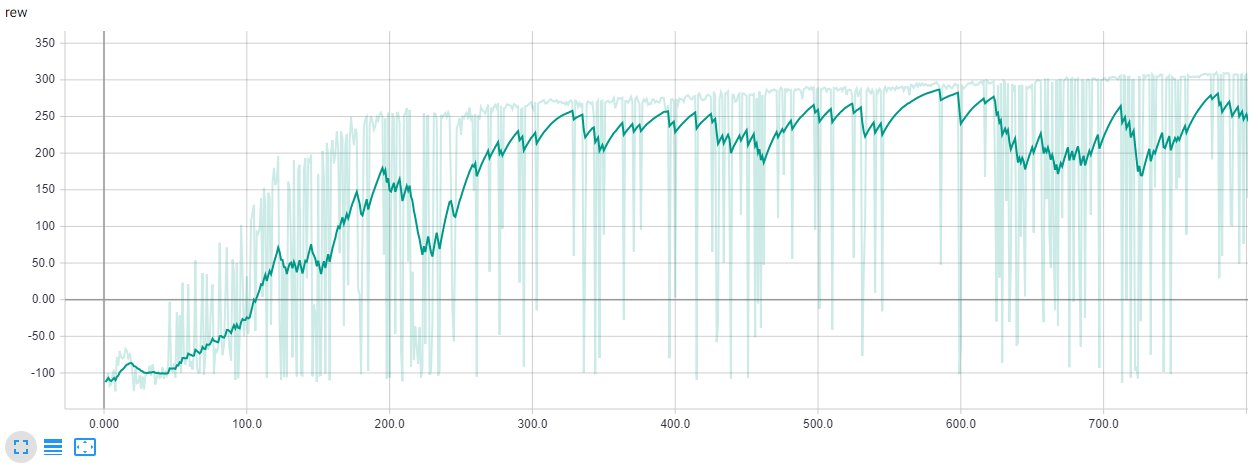
Results

In the plot below are shown the rewards. The game defines “solving” as getting an average reward of 300 over 100 consecutive trials. We aren’t at that level yet, but is possible to reach that goal tuning the hyperparameters and playing more episodes.
Install
pip install gym
pip install torch torchvision
pip install tensorboardX
apt-get install -y python-numpy python-dev cmake zlib1g-dev libjpeg-dev xvfb ffmpeg xorg-dev python-opengl libboost-all-dev libsdl2-dev swig
git clone https://github.com/pybox2d/pybox2d
cd pybox2d
!pip install -e .